-
Мастерство стандартной библиотеки: бесконечные итераторы itertools
Продолжаем наше исследование модуля
itertools.На очереди 3 конструктора бесконечных итераторов:
from itertools import count, cycle, repeat -
Мастерство стандартной библиотеки: itertools.chain
Представьте, что вам нужно пробежать за один проход по N коллекциям, например по двум вот таким.
In [2]: l1 = list(range(5)) In [3]: l2 = list(range(10)) In [4]: l1 Out[4]: [0, 1, 2, 3, 4] In [5]: l2 Out[5]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]Естественно, возникает желание написать вот такой цикл:
-
Прикольный трюк: сжатие csv файлов 'на лету' в pandas
Pandas - великолепный инструмент для работы с данными в python, а csv - де-факто стандартный формат хранения данных в Data Science (да и много где еще).
Однако, csv файлы могут занимать ооочень много места. Если Вы сохраняете какие-то промежуточные данные или регулярно делаете выгрузки из СУБД, то и количество этих файлов может быстро расти.
Если Вам приходится часто двигать файлы через сеть между различными окружениями - сервера/рабочая станция/Google Colab/Kaggle, то этот процесс может превратиться в настоящую головную боль. Большие файлы долго передаются по сети, дисковое пространство в сервисах быстро заканчивается и они начинают требовать от Вас апгрейдить аккаунт и расширять лимиты.
Но есть решение, причем удивительно простое и удобное.
-
Тепловые карты по децилям в plotly.express
Построить тепловую карту (как и почти любую визуализацию данных) в великолепной
plotly.expressневероятно просто:px.density_heatmap(df, x='x', y='y', z='z', marginal_y='histogram').show()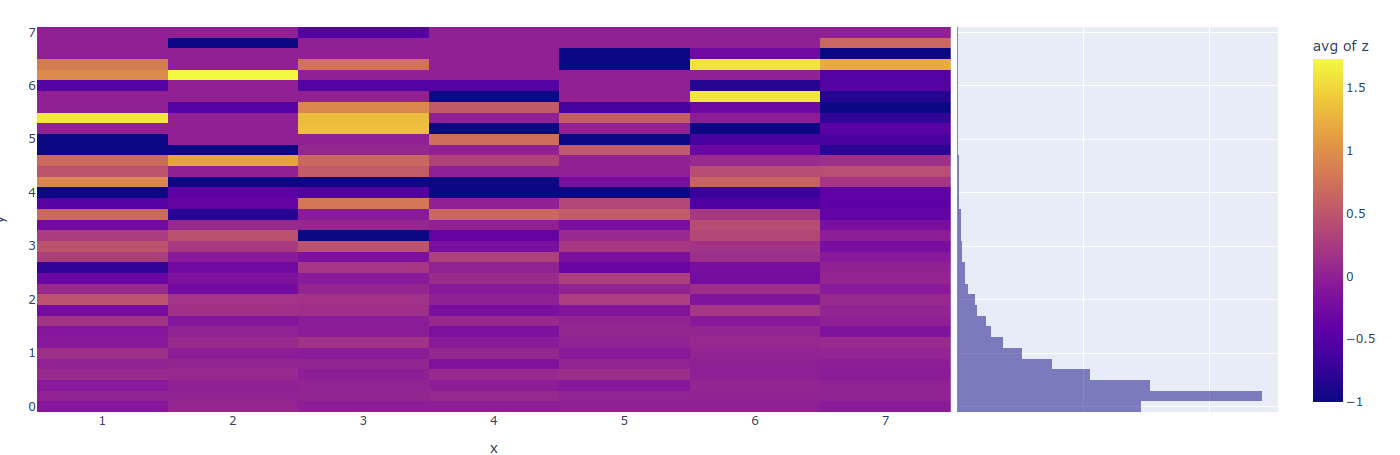
Но иногда хочется разбить данные на децили/квартили/квинтили. Как например, в нашем случае - по оси Y.
К сожалению, “из коробки”
plotly.expressне справится. -
Балансировка классов в torch с помощью WeightedRandomSampler
В машинном обучении постоянно встречается эта проблема - в датасете, на котором ты обучаешь нейросеть (или любую другую ML модель) - разное количество записей для разных классов. Иногда прям сильно разное. Если оставить это как есть, то нейросеть толком не выучит редкие классы и не научится их отличать.
Два основных подхода к решению этой проблемы - умножать loss для редких классов пропорционально их редкости, чтобы высокий loss заставлял сетку учиться на них и чаще читать записи редких классов, чтобы они перестали быть редкими. Эта статья про второй подход.